Figura 1
Durata di udelay
La figura è anche disponibile in PostScript
di Alessandro Rubini
Riprodotto con il permesso di Linux Magazine, Edizioni Master. Come viene visto lo scorrere del tempo in Linux-2.6
In queste pagine vengono introdotti i meccanismi usati dal kernel per la gestione del tempo: la rappresentazione dello scorrere del tempo, l'introduzione di ritardi durante l'esecuzione di un programma, la misura ad alta risoluzione degli intervalli di tempo.
Il meccanismo principale per la misura del tempo in spazio kernel è l'orologio di sistema, un dispositivo hardware che interrompre il processore con cadenza costante. La frequenza delle interruzioni generate è programmabile e viene impostata nell'hardware durante le prime fasi dell'avvio del sistema.
È sempre stato possibile scegliere la propria frequenza di
interruzione preferita assegnando la macro HZ in
<asm/param.h>, i cui valori preimpostati in pasato erano 1000 per
le macchine Alpha e 100 per quasi tutte le altre piattaforme.
Ora, in Linux-2.6, HZ vale 1000 anche su x86. È ancora possibile
modificare HZ prima di ricompilare il kernel e tutti i moduli, ma
il valore usato deve essere compreso tra 12 e 1535, come documentato
in <linux/jiffies.h>.
Cambiare il valore di HZ porta a un diverso comportamento del
sistema. In pratica, l'interruzione dell'orologio di sistema serve
per permettere al kernel di svolgere vari compiti, tra cui risvegliare
i processi che devono essere riattivati perché è scaduto il loro
timeout. Per esempio, quando un processo richiede di dormire per 20
millesimi di secondo, verrà risvegliato solo in concomitanza con
un'interruzione dell'orologio di sistema, non essendo disponibili
altre forme di temporizzazione (tranne che in casi speciali, che qui
non posso trattare). Se HZ vale cento, perciò,
un'attesa di 20ms durerà un tempo non prevedibile compreso tra
20ms e 30ms; se HZ vale mille, l'incertezza si riduce ad
1ms. Aumentare la cadenza delle interruzioni però significa
anche introdurre un maggior carico computazionale nel sistema, perché
ogni interruzione deve essere gestita a livello software.
Mentre con linux-2.4 e precedenti era comune ricompilare tutto con
HZ posto a 1000 (invece di 100), specialmente in contesto
industriale, oggi è molto raro ricompilare un kernel per PC con un
diverso valore di HZ anche per il limite massimo a 1535 (che impedisce
l'uso valori interessanti come 2000 o 5000).
Su ARM, dove il default è ancora 100, capita ancora di
modificare param.h per usare 1000, in situazioni particolari.
Quale che sia la cadenza dell'orologio di sistema, ad ogni colpo di
clock viene incrementata la variabile jiffies, dichiarata come
volatile unsigned long. Utilizzando jiffies e HZ, un
modulo può facilmente misurare gli intervalli di tempo. Queste
misure, nonostante la loro granularità, sono spesso sufficienti per
le esigenze dei driver, per lo meno per tutti i compiti macroscopici
come spegnere il motore del dischetto dopo l'uso o sapere se la
pressione di un tasto è la seconda di un "doppio-click" oppure un
nuovo evento "singolo-click".
Usando jiffies è possibile, per esempio, introdurre un ritardo
di un decimo di secondo (con l'incertezza già descritta) con codice
simile a questo:
unsigned long j = jiffies; /* non usare */
while (jiffies < j + 100) /* non usare */
; /* non usare */
volatile della variabile jiffies, in assenza del quale il
compilatore ottimizzerebbe l'accesso alla variabile e il ciclo non
avrebbe mai termine, in quanto confronterebbe sempre gli stessi due valori
e la condizione non diventerebbe mai falsa.
Il codice mostrato, però, contiene due errori relativamente comuni:
l'uso di un valore non parametrizzato per la misura del tempo e il
malfunzionamento in caso di overflow della variabile jiffies.
Il primo errore si risolve usando HZ/10 al posto di 100,
per garantire il corretto funzionamento in ogni sistema indipendentemente
da quale sia la cadenza dell'orologio di sistema. Il secondo errore si
risolve usando una delle macro offerte dal kernel per il confronto
dei tempi a e b, entrambi unsigned long:
time_after(a, b);
time_before(a, b);
time_after_eq(a, b);
time_before_eq(a, b);
jiffies sono molto difficili
da identificare, perché si verificano molto raramente e non sono
riproducibili fino al prossimo overflow, cioè una volta ogni 50
giorni (se HZ vale 1000) oppure una volta ogni 497 giorni (se
HZ vale 100), mentre nei processori a 64 bit non accade mai.
Le quattro macro restituiscono un valore vero o falso a seconda che il
numero a
rappresenti un istante dopo l'istante b, o prima di esso.
L'implementazione delle macro, in <linux/jiffies.h> è
estremamente semplice, ma il loro uso
evita di dover sempre pensare a quale sia il
modo giusto per confrontare due tempi.
Correggendo il codice precedente, il modo corretto per introdurre un ritardo di un decimo di secondo in una funzione del kernel è:
unsigned long to = jiffies + HZ/10;
while (time_before(jiffies, to))
;
to.
potrebbe durare anche svariati secondi, per esempio
se il driver deve aspettare il movimento di parti
meccaniche.
La soluzione corretta per introdurre una attesa di molti millesimi di
secondo in un driver è la seguente, dove msec indica il numero di
millesimi che si vuole aspettare:
set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(msec * HZ /1000);
msecs_to_jiffies per
convertire un tempo in millisecondi in un conteggio di cicli di
orologio. Nelle due righe di codice mostrate, il processo corrente
viene messo in stato sleeping (qui chiamato interruptible perché
l'arrivo di un segnale può interrompere il sonno del processo) e viene poi
dato il controllo allo scheduler perché esegua altri processi fino
allo scadere del tempo indicato.
Il codice mostrato si può solo usare nel contesto di un processo, ovvero nell'implementazione di una chiamata di sistema; se un gestore di interruzione o altro codice asincrono deve attendere, occorre riconsiderare il problema e risolverlo modificando la struttura del codice.
Normalmente, l'intervallo di tempo coperto da un unsigned long
è sufficiente per le esigenze del codice in spazio kernel, ma
in certi casi può essere necessario usare una marcatura temporale
che, pur nella granularità di HZ, sia unica e non sia soggetta
ad overflow.
Per questo motivo è stata introdotta la variabile jiffies_64, grande assente nelle precedenti versioni del kernel. Si tratta di una variabile a 64 bit su tutte le piattaforme supportate ed è perciò immune a problemi di overflow, perché anche con una interruzione dell'orologio ogni microsecondo impiegherebbe più di mezzo milione di anni ad esaurire la sua corsa.
Poiché sulle piattaforme a 32 bit non è possibile accedere atomicamente ad 8 byte, occorre proteggere gli accessi a jiffies_64, per evitare che il valore venga modificato dall'interruzione del timer mentre altro codice lo sta leggendo. È definita a questo fine la funzione
u64 get_jiffies_64(void);
<linux/jiffies.h> per i dettagli.
La cosa veramente interessante di jiffies e jiffies_64 è che
si tratta, in pratica, di una sola variabile invece che due. In
questo modo si
ottiene anche che i due valori sono sempre sincronizzati tra loro, anche
durante il loro aggiornamento.
Il linguaggio C permette di definire due nomi e due tipi per lo stesso
indirizzo di memoria solotramite il costrutto chiamato union. In
questo caso, però, non è possibile usare una union perché la
variabile jiffies deve per forza restare un intero lungo, come è
sempre stata e come si
aspetta tutto il codice già scritto. La variabile jiffies
viene perciò solo definita come extern: se si cerca nei file
.c e .h si troverà infatti la definizione di jiffies_64 nel
codice di piattaforma (per esempio, arch/i386/kernel/time.c) ma
non la definizione di jiffies, solo la sua dichiarazione esterna.
La definizione di jiffies, in effetti, non avviene a livello di
codice C ma a livello di linker, nel file vmlinux.lds.S di
ogni piattaforma. Nel riquadro 1 viene mostrato come viene
definito jiffies nelle varie piattaforme.
È interessante notare come jiffies_64 non venga preimpostato a
zero ma al valore INITIAL_JIFFIES, definito come:
((unsigned long)(unsigned int)(-300*HZ))
0xfffb6c20 se HZ vale 1000, è stato scelto per
garantire un overflow della metà bassa della variabile cinque
minuti dopo l'avvio del sistema. Questo ha permesso e tuttora permette
di diagnosticare possibili problemi legati all'overflow di
jiffies senza aspettare 50 giorni. La conversione prima in
int e da qui in long serve per garantire che la metà alta di
jiffies_64 rimanga zero anche nei processori a 64 bit, nei quali
int è un numero a 32 bit ma long è a 64 bit.
Riquadro 1 - definizione della variabile jiffies
|
Il linker (
Il lavoro del linker viene controllato da un "linker script"
(ld script,
La definizione di
In sistemi big-endian, invece, i 32 bit meno
significativi sono memorizzati dopo quelli più significativi; in
|
Per permettere ai driver di richiedere brevi ritardi nell'esecuzione, tipicamente per dilazionare una seconda operazione sull'harwdare dopo averne appena effettuata una, il kernel implementa un ciclo di attesa completamente software, in quanto l'orologio di sistema ha una granularità troppo elevata per questi compiti.
Per calibrare il proprio ciclo di attesa, il kernel all'avvio
misura le prestazioni del processore nell'esecuzione di uno stretto
ciclo di conteggio e stampa il numero di bogoMIPS misurati.
Tale numero rappresenta i milioni di istruzioni svolte ogni secondo (MIPS) durante l'esecuzione di quello specifico ciclo di elaborazione, lungo due istruzioni. La misura del tempo durante la calibrazione di questo ciclo è, ancora, data dall'interruzione dell'orologio di sistema.
Vengono così dichiarate tre funzioni in <linux/delay.h>:
void mdelay(int n);
void udelay(int n);
void ndelay(int n);
n millisecondi, microsecondi, nanosecondi. Il livello di precisione
raggiunto varia da piattaforma a piattaforma, come esplicitato
in delay.h, che definisce mdelay ed ndelay sulla base
di udelay per le piattaforme che non offrono tali funzioni nativamente.
In tutti e tre i casi, la funzione chiamata introduce un ritardo pari o superiore alla durata richiesta, ovviamente nei limiti della precisione raggiungibile con un ciclo software e della tolleranza del quarzo che pilota l'orologio di sistema.
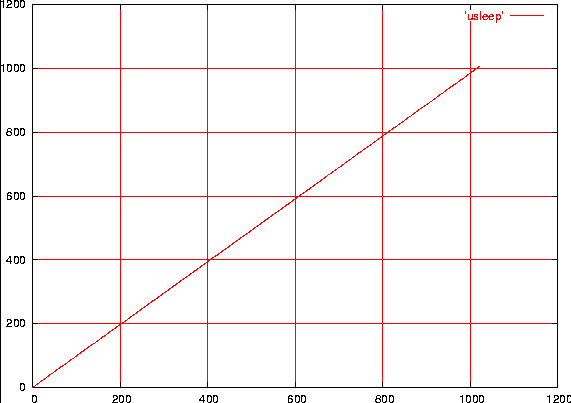
In figura 1 è rappresentata la durata, in microsecondi, di chiamate
successive alla funzione udelay con argomento che varia da 0 a 1023,
raccogliendo i dati su un PC relativamente recente con
linux-2.6.10-rc3. In figura 2 è rappresentata la durata, in
nanosecondi, di chiamate a ndelay con argomento da zero a 250. Si
nota come la piattaforma x86 implementi nativamente ndelay e come la
precisione nella generazione di ritardi molto piccoli sia più
grossolana, come ci si poteva aspettare.
Figura 1
Durata di udelay
La figura è anche disponibile
in PostScript
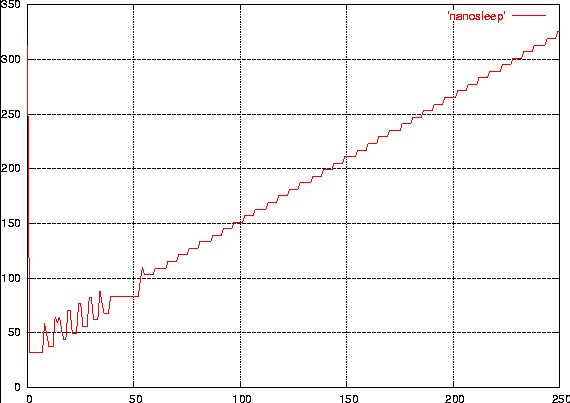
Figura 2
Durata di ndelay
La figura è anche disponibile
in PostScript
All'informatico spesso servono misure di ritardi molto precise, per esempio per valutare il tempo di esecuzione delle procedure e poterne ottimizzare la resa. Il conteggio dei cicli dell'orologio di sistema è una misura inaccettabilmente grossolana a questi scopi, indipendentemente dalla velocità del processore: un processore più veloce può gestire più interruzioni, ma solo perché svolge più lavoro nello stesso lasso di tempo; non possiamo mai avere più di una interruzione ogni molte migliaia di istruzioni macchina, ma un'interruzione molto frequente modifica sostanzialmente le prestazioni del sistema sotto esame, rendendo vana la misura.
Per risolvere questo problema, molti processori moderni (per esempio gli x86 a partire dal Pentium, molti PowePC, i processori PXA all'interno della famiglia ARM) contengono un registro che conta i cicli di clock del processore e un meccanismo per leggere tale registro. In questo modo, un programma può leggere il contatore prima e dopo la sezione di eventi che intende misurare e calcolare la differenza. Questo è il modo, per esempio, in cui il modulo timecheck ha misurato la durata di udelay e ndelay per generare le figure mostrate in queste pagine.
L'header <asm/timex.h> definisce il tipo cycles_t e la
funzione get_cycles. Se il processore ospite offre un contatore di
cicli, la funzione ne ritorna il valore al chiamante; se il processore
non lo offre, viene ritornato zero come accade, per esempio, su un 486).
Ecco quindi come è fatto il ciclo di calcolo di timecheck.c:
t0 = (u32) get_cycles();
udelay(i);
t1 = (u32) get_cycles();
array[i] = (t1 - t0)/((cpu_khz+500)/1000);
u32 (interi senza segno a 32 bit) raccolgono il
contatore di cicli prima e dopo la richiesta di attesa, mentre
l'assegnamento finale converte da conteggio di cicli di clock
a numero di microsecondi, dividendo il conteggio per la frequenza
in MHz del processore.
Siccome il tipo cycles_t può essere a 32 o a 64 bit (64 bit nel
PC), è stata esplicitata la conversione a u32 nell'assegnamento
di t0 e t1.
|
Il programma timecheck, disponibile presso
http://www.linux.it/kerneldocs/time/src.tar.gz, misura
la durata di udelay o ndelay sulla macchina ospite allocando una pagina
di memoria dove ospitare il vettore dei risultati. Tale pagina viene
resa disponibile tramite un miscdevice, cui si può accedere solo
tramite mmap senza controlli specifici (perciò a qualunque offset
specificato corrisponde sempre la stessa pagina di memoria).
Queste scelte minimaliste sono volte a
tenere il codice il più semplice e compatto possibile, in quanto in
questa sede interessa solo la misura dei tempi e non la gestione di un
miscdevice.
La parte significativa di timecheck è rappresentata nel Riquadro 2.
Il numero di misure effettuate dipende dalla dimensine della pagina sulla macchina ospite e ogni campione è un numero a 32 bit. Questo nel caso del PC porta ad un vettore di 1024 campioni. I campioni vengono raccolti al caricamento del modulo, disabilitando le interruzioni per ogni misura effettuata. Come mostrato nel codice del riquadro 2, il parametro docli può essere posto a zero per richiedere la misura senza disabilitare le interruzioni; il parametro nsec, se non-zero, richiede la misura di ndelay invece che udelay, e in questo caso i campioni salvati nel vettore sono i cicli di clock invece che i microsecondi.
Per usare il modulo, occorre creare un file speciale con major number 10 (misc) e minor number come riportato in /proc/misc dopo il caricamento del modulo. Quasi sicuramente troverete 63. Il file speciale può quindi essere creatoc on questo comando:
mknod /dev/tc c 10 63
./mapper /dev/tc 0 4096 | od -t d4 -An -w4 -v > /tmp/log
-t d4), senza un colonna riportante l'indirizzo di ogni numero
(-An), quattro byte per ogni riga
(-w4) e in forma prolissa (senza eliminare le ripetizioni: -v
per verbose).
Il file ASCII così salvato si può visualizzare semplicemente con
gnuplot (comando plot '/tmp/log'), col quale sono state generate
le figure qui riprodotte.
Se è stato specificato nsec=1 caricando il modulo, i numeri
raccolti rappresentano cicli di clock e vanno convertiti in
nanosecondi dividendo per la frequenza del processore
espressa in GHz. La conversione
non viene fatta in spazio kernel perché in tale contesto non si può
usare la virgola mobile ed è inutile usare strani trucchi
per ottenere un risultato preciso in aritmetica intera.
Nella macchina usata per le prove, /proc/cpuinfo riporta
1833.218 MHz, quindi il file è stato convertito con questo comando,
dopo od nella pipe mostrata poco più sopra:
awk '{printf "%f\n", $1/1.833218}'
docli=0); le piccole deviazioni dalla diagonale
sono dovuti a ritardi ulteriori indotti dalle interruzioni hardware:
quelle dell'orologio di sistema e quelle del disco con DMA abilitato.
In figura 4 è riporta la stessa
misura ma durante un trasferimento dati dal disco IDE, dopo aver
disabilitato il DMA. Nel primo caso i ritardi vengono prolungati di
pochi microsecondi mentre nel secondo caso si vedono ritardi fino a
600 microsecondi. Normalmente questa incertezza nei ritardi non è un
problema, in quanto al software interessa quasi sempre dilazionare
l'esecuzione di almeno il tempo richiesto. Per le applicazioni in
cui questo comportamento non è accettabile, occorre inevitabilmente
abbandonare le API del kernel Linux e passare ad un sistema
di tempo reale stretto come RTAI.
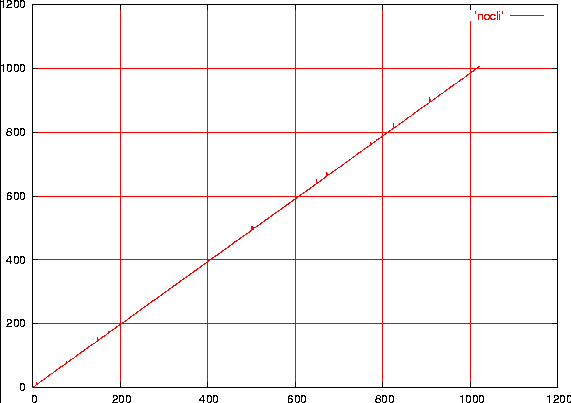
Figura 3
Durata di udelay con le interruzioni abilitate
La figura è anche disponibile
in PostScript
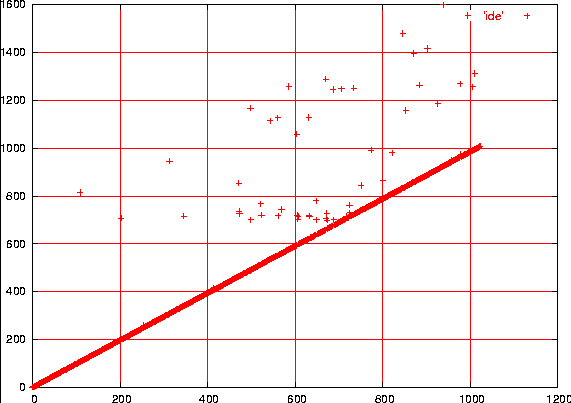
Figura 4
Come figura 3, ma con forte attività del disco IDE
La figura è anche disponibile
in PostScript