Figura 1
Inizializzazione dei puntatori
La figura è anche disponibile in PostScript
di Alessandro Rubini
Riprodotto con il permesso di Linux Magazine, Edizioni Master.
Il termine filesystem viene usato per indicare diversi aspetti del sistema GNU/Linux, a diversi livelli. Normalmente con filesystem si indica la struttura dati ad albero in cui risiedono tutti i file accessibili ad una specifica macchina oppure, in base al contesto, un sottoinsieme di tali file, salvati in uno specifico dispositivo di memorizzazione. Per un programmatore di sistema, d'altra parte, il termine è sovente usato per indicare il codice che si occupa dell'organizzazione dei dati e della presentazione all'utente come albero di file.
In queste pagine il termine filesystem viene usato in questo significato, con riferimento al codice sorgente che realizza una specifica modalità di organizzazione dei file piuttosto che all'insieme dei file stessi; per quest'ultimo concetto viene qui usato il termine alberatura, per evitare ambiguità. Il codice presentato è stato provato sulla versione 2.6.11-rc4 del kernel.
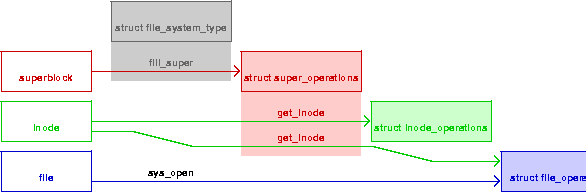
Un filesystem è normalmente composto da tre strutture dati che ospitano puntatori a funzioni per svolgere operazioni su tre tipi di oggetti: il superblocco, l'inode e il file.
La registrazione di un filesystem viene effettuata chiamando la
funzione register_filesystem, il cui argomento è una struttura
dati che descrive il filesystem tramite il suo nome e due puntatori
a funzione: get_sb, usata per leggere il superblocco al momento
del mount, e kill_sb che viene invece chiamata quando viene
smontata l'alberatura.
Il superblocco è la struttura dati che tiene traccia dello stato
dell'albertatura. Il suo nome deriva dalla posizione storicamente
occupata dalla struttura dati su disco, cioè il primo blocco della
partizione dati. Poiché la struct super_block che risiede nella
memoria dell'elaboratore non è più la copia letterale del primo
blocco della partizione del disco, il lavoro di get_sb risulta
abbastanza complesso e fortemente dipendente dal tipo di filesystem.
Le operazioni sul superblocco, il cui puntatore viene
istanziato da get_sb all'interno della stessa
struct super_block, sono la lettura e la scrittura di inode,
la gestione delle quote (occupazione associata ad ogni utente)
sull'alberatura, la raccolta di informazioni statistiche (spazio di
disco disponibile) e la gestione della concorrenza sull'alberatura.
Una di tali operazioni, get_inode, compila la struttura dati
inode, istanziando tra le altre cose i puntatori
struct inode_operations
e struct file_operations relative all'inode.
L'inode è la struttura dati che contiene le meta-informazioni asociate ad ogni file, come il proprietario, la data e l'ora di accesso o di modifica, la lunghezza, i permessi di accesso. Le operazioni sull'inode sono la creazione e la distruzione dell'oggetto, il cambiamento di nome, le modifiche nei permessi di accesso e la gestione degli "attributi estesi", che esulano dall'argomento di questo articolo.
Il file, infine, è la struttura dati che rappresenta la singola
istanza di file aperto, come viene visto all'interno del kernel. Si
tratta dell'oggetto su cui vengono fatte le operazioni di lettura e
scrittura, ioctl, mmap, eccetera. Per i file regolari, la
struct file_operations da usarsi viene specificata dal codice di
filesystem; per i file speciali, invece, le operazioni sono definite
da codice specifico nel kernel (per FIFO e socket, per esempio) o nel
device driver appropriato (per i file speciali a caratteri o a
blocchi). Il puntatore alle operazioni sul file viene istanziato
in ogni file al momento della sua apertura, da parte della chiaamta
di sistema sys_open. In figura 1 sono rappresentate le tre
strutture dati ed i puntatori alle operazioni relative, insieme
alla funzione che istanzia ciascuno di essi.
Le tre strutture dati appena descritte, unitamente a struct dentry
(directory entry) che non ricopre un ruolo importante nel
codice di filesystem, formano il cosiddetto VFS, virtual file system,
cioè il livello astratto usato dal kernel per lavorare
con i file, che risulta indipendente dallo specifico tipo
di filesystem usato per la memorizzazione.
Il codice per registrare un filesystem
somiglia a quello rappresentato nel riquadro 1. Tale codice si
riferisce ad un filesystem senza dispositivo di appoggio (come
spiegato più avanti), ed è disponibile insieme agli altri
esempi di questo articolo in
http://www.linux.it/kerneldocs/filesystem/src.tar.gz.
Si noti come a causa della complessità delle strutture dati coinvolte nella
gestione di un filesystem, il kernel esporti alcune funzioni per
evitare inutile duplicazione di codice nel compilare le strutture
dati. Il modulo di esempio utilizza tali funzioni ove possibile.
Una volta caricato il module, è possibile montare e smontare questo filesystem senza errori, ma ogni chiamata di sistema invocata al suo interno fallisce in quanto non sono definite operazioni sugli inode né sui file. Per esempio, nel riquadro 2 è mostrato l'errore che si ottiene nel leggere la directory radice dell'alberatura.
Il ruolo di un filesystem normalmente è quello di permettere l'accesso ad un'alberatura, appoggiandosi su un dispositivo a blocchi per la memorizzazione. Tale dispositivo può essere un disco rigido, ma anche qualsiasi meccanismo di memorizzazione dati per cui sia disponibile un driver che ne permette l'accesso secondo le API dei dispositivi a blocchi. Per esempio, tramite il driver di ramdisk si possono salvare file in memoria RAM e tramite il supporto mtdblock (parte del sottosistema MTD, memory technology device) si può accedere alla memoria flash dei sistemi embedded come se si trattasse di un disco.
In questa situazione, è normale per il dispositivo a blocchi oltre a contenere i dati associati ai singoli file e alle tabelle di allocazione dello spazio, immagazzinare anche una copia su disco delle strutture inode, per memorizzare le meta-informazioni relative ai file, rispecchiando il ruolo della struttura dati usata dal kernel in memoria RAM. L'organizzazione dei dati e degli inode sul dispositivo fa parte della struttura dati realizzata dal filesystem.
In alcuni casi, la struttura dati istanziata sul dispositivo fisico non contiene tutte le informazioni normalmente usate all'interno del kernel. Questo succede per esempio per strutture di memorizzazione obsolete e inefficienti come FAT e VFAT, che purtroppo ci troviamo ancora a dover usare in certi contesti -- e se non fosse per il lavoro di EFF e altri dovremmo pure pagare il dazio su ogni dispositivo fisico che "benefici" di tale abomiveole "tecnologia". L'implementazione del filesystem, in questi casi, nasconde alcune delle limitatezze del formato di memorizzazione sottostante restituendo valori costruiti su misura per le informazioni mancanti ed evitando di salvare su disco gli attributi non rappresentabili, come il proprietario del file e la data/ora dell'ultimo accesso ai dati. Alcune operazioni, come la creazione di file speciali, saranno comunque non disponibili, ma nel complesso l'utente non noterà grandi limitazioni nell'uso di questi filesystem per il salvataggio di dati personali.
Alcuni filesystem convenzionali, a differenza del caso
discusso, non si appoggiano su di un
dispositivo a blocchi. Questo accade, per esempio, con i filesystem
di rete come NFS o SMB. Le operazioni sugli inode e sui file, in
questo caso, vengono evase tramite richieste inoltrate attraverso la
rete IP, senza bisogno di associare l'alberatura ad un dispositivo a
blocchi. Tali filesystem sono caratterizzati dall'attributo nodev,
riportato per esempio in /proc/filesystems.
L'idea di un filesystem di tipo nodev viene portata al suo
limite con realtà come /proc, in cui le informazioni restituite ai
processi sotto forma di alberatura non rappresentano informazione
recuperata da qualche tipo di memoria di massa (locale o remota) ma
realizzano semplicemente una finestra sulle strutture dati interne al
kernel. Nonostante la sua atipicità, proc ci accompagna da più
di dieci anni e può considerarsi
a pieno titolo un filesystem convenzionale del kernel Linux.
Con il crescere della potenza di calcolo disponibile nei microcontrollori, l'uso di sistemi GNU/Linux in tali contesti è andato crescendo notevolmente. Questi ambienti operativi, diversi dal più noto elaboratore personale o server di rete, hanno sollevato esigenze diverse anche per quanto riguarda i filesystem; in particolare è diventato importante poter limitare l'occupazione di memoria associata ad una alberatura relativamente completa, mentre è sempre più comune poter memorizzare buona parte del sistema su memoria in sola lettura.
Proprio l'utilizzo in ambienti relativamente ridotti, in cui la disponibilità di potenza di calcolo abbonda, a scapito dello spazio di memorizzazione utilizzabile, ha portato alla nascita di un certo numero di filesystem con inode molto ridimensionati, spesso associati alla possibilità di comprimere i dati nel dispositivo di memorizzazione.
Il primo esempio di filesystem ridotto è stato storicamente il romfs, il cui sorgente è composto da soli 15kB di codice, nell'unico file fs/romfs/inode.c. Si tratta di un filesystem di sola lettura non compresso, in cui il superblocco e l'inode occupano solo 16 byte (più il nome del file). Naturalmente questa riduzione in dimensione si è ottenuta a scapito di buona parte dell'informazione normalmente contenuta nell'inode, come il proprietario e il gruppo di appartenenza del file, i permessi di accesso (tutti eliminati, tranne il bit del permesso di esecuzione), i tre marcatori di tempo associati al file.
Il romfs viene spesso usato come filesystem nei sistemi estremamente piccoli, come alcuni processori senza MMU della famiglia m68k, sistemi in cui il costo computazionale di decompressione dei sarebbe superiore ai vantaggi dati dal risparmio in ingombro.
Un altro esempio significativo, più recente, di filesystem ridotto è cramfs, il cui nome viene dal verbo to cram: stipare, ammassare. La struttura dati è in sola lettura e ospita file compressi, unitamente ad inode di soli 12 byte, più il nome del file. La riduzione ulteriore dell'inode è stata ottenuta limitando il numero di bit associati alla dimensione del file (che non può superare i 16MB di dimensione) e ad altri campi di bit, liberando nel frattempo alcuni bit per memorizzare il proprietario e il gruppo del file. La compressione dei dati viene effettuata una pagina alla volta, per sftuttare al meglio i meccanismi interni di gestione dei dati, descritti in seguito.
Per stipare l'alberatura in un file binario, da trasferire poi sul dispositivo di memorizzazione nella macchina finale (memoria flash o altro dispositivo), si usa l'applicativo mkcramfs, che copia un intero albero di directory in un univo file di tipo cramfs. Allo stesso modo, mkromfs è lo strumento che crea un'immagine binaria romfs a partire da un'alberatura.
Qualunque sia il tipo di filesystem in uso, la lettura e la scrittura dei file avviene per pagine di memoria. La dimensione di una pagina dipende dalla piattaforma e in alcuni casi, come IA64, può essere scelta tra più opzioni al momento della compilazione del kernel; la dimensione di pagina più comune è 4kB ma può arrivare fino a 64kB. Se un processo legge anche un solo byte da un file, il kernel alloca comunque un'intera pagina di memoria e richiede il trasferimento di tutto il suo contenuto dal dispositivo di memorizzazione. La struttura dati che gestisce le pagine di memoria associate ai file su disco si chiama page cache.
La strutturazione per pagine del trasferimento dati relativo ai file è estremamente vantaggiosa, perché se pure occorre più memoria di lavoro nell'accesso ai file, è anche vero che si limitano i trasferimenti da e verso la memoria di massa, permettendo nel contempo l'accesso diretto al contenuto di un file utilizzando la MMU di sistema, eliminando quindi inutile copie dei dati.
La chiamata di sistema mmap, per esempio, può essere soddisfatta semplicemente rendendo visibili nello spazio di indirizzamento del processo le pagine di memoria relative al file richiesto. La coerenza dei dati tra processi che usano mmap e processi che usano read/write è garantita dal fatto che tutti i trasferimenti da e per la memoria di massa passano attraverso la page cache. L'importanza di mmap è fondamentale in quanto ogni qual volta viene eseguito un programma, l'accesso al codice e ai dati dell'applicativo è realizzato proprio tramite mmap, che come abbiamo visto sfrutta al meglio la page cache.
Si noti che la page cache viene coinvolta in qualunque trasferimento dati da e verso un'alberatura, indipendentemente dal tipo di filesystem in uso e dal dispositivo di memorizzazione usato. Anche quando si sta lavorando su un ramdisk, perciò, il contenuto dei file deve essere replicato in page cache per poter essere accessibile da parte dei processi. Questo implica, tra le altre cose, che un programma eseguibile o una libreria di funzioni che risiedono in un ramdisk, non appena vengono usati risiedono anche in page cache come memoria di lavoro. Questo spiega, tra le altre cose, perché la compressione di cramfs sia realizzata secondo una divisione in pagine invece di comprimere ciascun file nel suo complesso.
Questa onnipresenza della page cache ha portato alla creazione di tmpfs: un sistema di memorizzazione dei file nella page cache stessa, senza alcun dispositivo di memorizzazione associato. Quando si monta un tmpfs, l'alberatura associata è vuota; nel momento in cui si scrive al suo interno, le pagine dati che normalmente verrebbero salvate su memoria di massa e successivamente eliminate dalla memoria RAM vengono segnate "in uso" e perciò persistono in RAM, finchè i dati non vengono cancellati o il filesystemviene smontato. Lo stesso accade con gli inode che contengono le meta-informazioni relative ai file in tmpfs.
In questo modo, il tmpfs si espande e si riduce in base all'uso che ne viene fatto, senza richiedere mai il salvataggio su dispositivi esterni dei dati ivi contenuti. Non solo: la esecuzione di programmi e l'accesso in mmap ai dati al suo interno non richiede la copia aggiuntiva necessaria in tutti gli altri filesystem. Mentre, cioè, una bash o una libc in un ramdisk sono presenti due volte in memoria RAM (sia nell'alberatura del ramdisk sia in page cache), il contenuto di tmpfs è presente in RAM una volta sola.
Questa strutturazione come filesystem della memoria di lavoro è
estremamente utile in diverse circostanze. Oltre all'ovvio uso come
albero /tmp in sistemi dotati di notevoli quantità di memoria,
tmpfs si rivela estremamente utile come supporto per le alberature
di sistemi incorporati con poca disponibilità di memoria flash. In
questo caso, è possibile, una volta avviato un sistema minimale in
ramdisk, montare un tmpfs dentro cui scompattare l'alberatura
delle applicazioni, memorizzata su flash in formato .tar.gz: l'uso di
memoria flash risulta così ridotto in quanto la compressione dell'intera
alberatura è più efficiente della compressione delle singole pagine;
l'uso di memoria RAM, d'altra parte,
rimane limitato alla sola copia di lavoro dei file.
Associando tmpfs a initrd e ad un uso creativo della chiamata di sistema pivot_root (due argomenti che purtroppo esulano dalla materia trattata questo mese), condendo il tutto con una buona dose di sudore della fronte, è addirittura possibile ricopiare tutta l'alberatura di sistema su tmpfs e disfarsi della ridondante copia dei file presente nel ramdisk di avvio. Non è invece possibile montare un tmpfs come alberatura di avvio del sistema, in quanto un tmpfs viene montato sempre vuoto e può essere riempito solo in un secondo momento.
L'implementazione di tmpfs risiede in mm/shmem.c e, in alternativa, in mm/tiny-shmem.c. La versione completa si appoggia sullo spazio di swap ove necessario, mentre la versione tiny è estremamente semplificata, per sistemi senza swap, e si basa sul codice in fs/ramfs/inode.c. La scelta di quale versione utilizzare viene effettuata durante la configurazione del kernel.
La strutturazione dell'informazione interna al kernel sotto forma di filesystem si è rivelata estremamente comoda nel tempo, per cui gli autori del kernel hanno un po' alla volta incorporato dentro a questa astrazione un certo numero di funzionalità di base. Per questo motivo in /proc/filesystems oggi troviamo un sockfs (implementato in net/socket.c), un bdev (da fs/block_dev.c), un pipefs (da fs/pipe.c), un futexfs (da kernel/futex.c) e vari altri filesystem, oltre al già noto devpts di cui abbiamo parlato in LM42.
Molti di questi filesystem speciali non possono essere montati dall'utente nell'alberatura di sistema: il loro ruolo è quello di far rientrare nell'astrazione file/inode quegli oggetti del kernel che vengono già referenziati attraverso descrittori di file, per una maggiore chiarezza e manutenibilità del codice sorgente. A beneficio di questi pseudo-filesystem, per evitare inutile duplicazione di codice, sono state raccolte molte funzioni di utilità in fs/libfs.c.
Alcuni di questi filesystem speciali, invece, sono stati scritti con l'esplicito intento di essere montati nell'alberatura di sistema, perprio come devpts che va montato in /dev/pts. Il caso più noto è usbfs che permette, tramite libusb, l'accesso diretto alle periferiche USB di tipo bulk da parte dei programmi utente; è così per esempi che gphoto2 scarica le fotografie dalle macchine digitali dotate di interfaccia USB.
Un'aggiunta estremamente recente nel panorama dei filesystem
speciali è debugfs, introdotto in Linux-2.6.11-rc1 con l'intento di
«cominciare a togliere roba da /proc e /sys». Si tratta di
una semplice infrastruttura per l'esportazione verso lo spazio utente
di variabili di configurazione o diagnostica
contenute dei driver o altro codice del kernel.
Al momento (Linux-2.6.11-rc4), sono
diponibili le primitive per esportare variabili intere senza segno di
8, 16 o 32 bit e interi booleani a 32 bit (valori
rappresentati come Y e N),
oltre ad una più generica debugfs_create_file, in cui
il chiamante fornisce una struct file_operations per poter avere
la massima flessibilità nella gestione del proprio file diagnostico.
Il modulo bug.c, riportato nel riquadro 3, mostra come usare
debugfs. Il codice riportato crea una directory bug, dentro cui
rende disponibile un file per ognuno dei tipi supportati.
Mentre le variabili a 8 e 16 bit sono definite nel sorgente stesso,
come variabile a
32 bit si è usata la variabile jiffies, il numero di colpi
dell'orologio di sistema dall'avvio della macchina. In questo modo
è facile verificare come il valore rappresentato in debugfs rispecchi
le variazioni interne al kernel. Si noti però
come l'uso di jiffies, un unsigned long,
tramite un puntatore a u32 è un pessimo esempio di programmazione,
qui adottato solo per mantenere breve l'esempio: si tratta di codice
intrinsecamente non portabile che in questo caso si comporta erroneamente
su macchine big-endian a 64 bit.
Il riquadro 4 mostra, tramite alcuni comandi di shell, il comportamento di debugfs. Si tratta, a ben vedere, di un'implementazione ancora zoppicante in alcuni dettagli, come tutte le novità che devono ancora maturare. Non descriverò qui le sue imperfezioni, perché probabilmente nella versione 2.6.11 questi errori di gioventù saranno già stati corretti.
Figura 1
Inizializzazione dei puntatori
La figura è anche disponibile
in PostScript
Riquadro 1 - un filesystem vuoto
|
|
Riquadro 3 - le API di debugfs
|
|
|
I file |