Fig. 1
La costruzione di un sito web viene completata con l'analisi degli accessi per verificare quanto il sito sia visitato e quanti e quali documenti siano tra i più richiesti. L'analisi delle stringhe per la ricerca digitate può inoltre aiutare a rendere i documenti più accessibili in base alle preferenze.
La comunità Open Source mette a disposizione due validi strumenti: ‘webalizer’ per le statistiche di accesso ed ‘ht://Dig’ (recensito nello scorso numero) come motore di indicizzazione delle pagine web. Questi prodotti sono distribuiti con licenza GPL (GNU public license) e sono reperibili per ogni distribuzione LiNUX agli indirizzi: http://www.webalizer.com e http://www.htdig.org.
Webalizer è un'applicazione client che legge e analizza i file di log generati da un applicativo server (tipo Apache o Squid) e produce statistiche in formato HTML. L’analisi dei risultati viene rappresentata in formato grafico per facilitarne la lettura ed anche in formato testuale con voci ripartite in più colonne.
I formati di file supportati sono lo CLF (common log format) generato da server web tipo `apache’,lo xferlog e lo squid proxy log generati dal server ftp tipo 'wu-ftp’ e dal proxy server ‘squid’.
L'avvio di webalizer avviene con il comando digitato al prompt di sistema:
[root@ /root]# webalizer
L’applicazione webalizer accetta sia una nutrita gamma di opzioni, sia più file di configurazione (quello per default è /etc/webalizer.conf) laddove i report da generare siano più di uno; per esempio uno per il web server ‘apache’, uno per il server ftp ‘wu-ftpd’ ed infine uno per il proxy server ‘squid’.
Allo scopo è preferibile l'opzione ‘-c’ come nel seguente comando.:
[root /root]# webalizer -c /etc/webalizer.conf /var/log/httpd/access_log
oppure per un file di log per server ftp:
[root /root]# webalizer -c /etc/webalizer-ftp.conf /var/log/xferlog
Tuttavia le opzioni da passare in linea di comando hanno una equivalente parola chiave nel file di configurazione, per questo ci limiteremo a descrivere solamente questo ultimo metodo.
Un file di history (statistiche precedenti) viene altresì generato se si abilita l'analisi incrementale, scelta indispensabile se i file di log sono ruotati da una applicazione cron; questo meccanismo comporta un tempo sensibilmente più lungo per completare l'operazione, tuttavia garantisce che le statistiche siano coerenti con i dati letti.
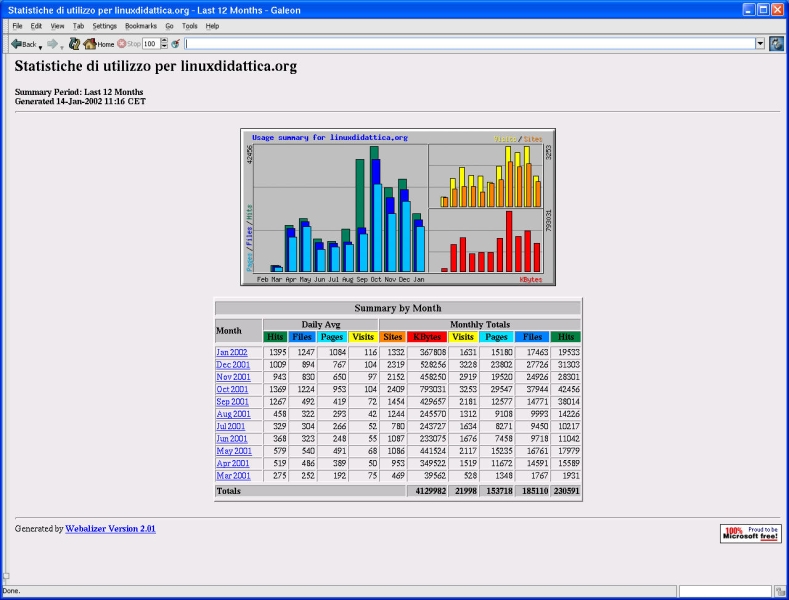
L'output generato da webalizer è composto da più report in formato html e grafici in formato PNG per ogni mese di attività ed una pagina di sommario che raccoglie gli ultimi dodici mesi di statistiche (index.html). Si veda la Figura 1.
In Figura 2 vi è il sommario dell'accesso giornaliero al server Web del mese corrente. Le tabelle con i valori numerici sono riassunte con un grafico ad istrogrammi. Uno a torta invece suddivide gli accessi per nazione di provenienza (Figura 3), mentre in Figura 4 si vedono le stringhe di ricerca digitate nel form della home page ed inviate all'applicazione htdig.
Per concludere nelle Figure 5 come il sito è (ben voluto e ricercato) dai motori di ricerca (sic!).
Fig.
1
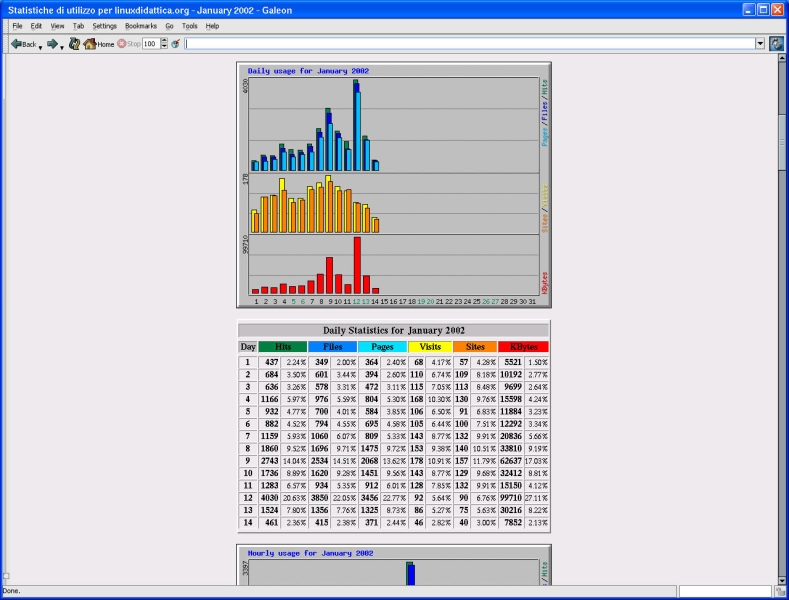
Fig. 2
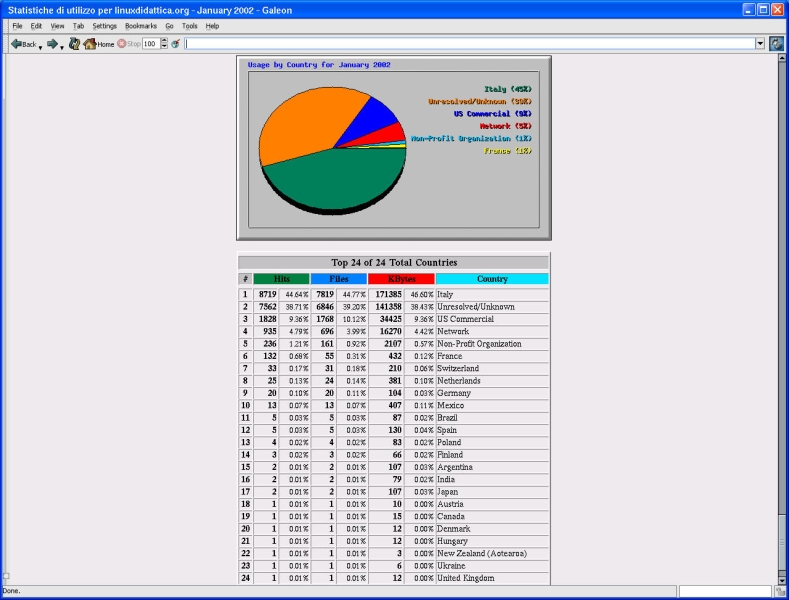
Fig.
3
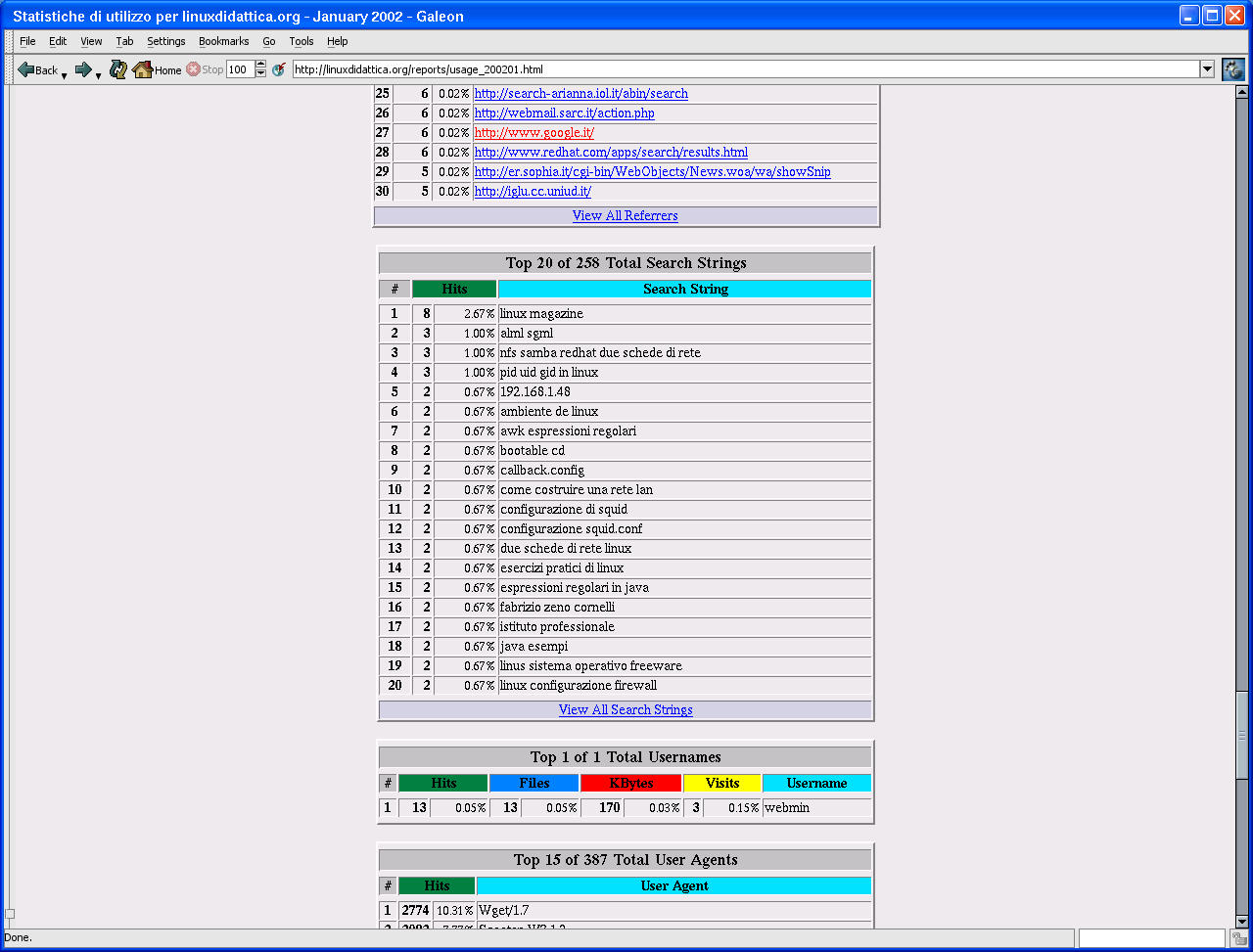
Fig.
4
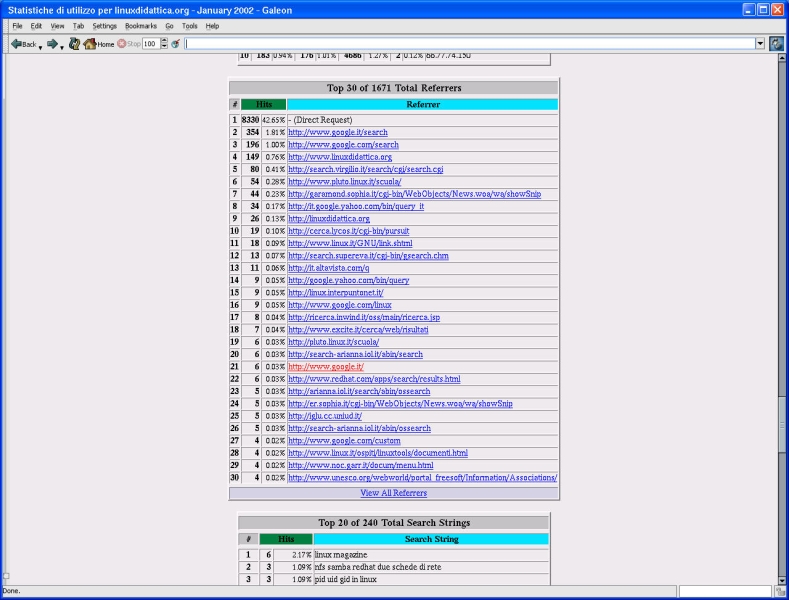
Fig.
5
Se l'introduzione ha convinto il lettore parliamo di informatica seria! - Stop ai colori ed armatevi di vi o emacs... -
Di seguito un file di configurazione autoesplicativo.
# file /etc/webalizer.conf # # Il percorso completo del nome del file da analizzare. # In questo esempio è il log generato dal server web apache LogFile /var/log/httpd/access_log # Il tipo di formato di log da analizzare. Webalizer si # aspetta in input un file CLF. # i valori che può assumere sono:'clf', 'ftp' o 'squid'. LogType clf # La directory di uscita dove memorizzare i file di output. # Se non viene specificata viene usata la directory corrente. OutputDir /var/www/html/reports # Rappresenta il nome del file che memorizza i dati degli ultimi # dodici mesi di log per generare la pagina index.html. # Se non viene specificato nessun percorso, ma solo il nome del # file esso è relativo al parametro OutputDir. HistoryName webalizer.hist # Porre a yes se si vuole usare il processo incremntale, utile # in presenza di file di log che ruotano almeno due volte al mese. Incremental yes # Come per il parametro HystroyName, solo relativo al processo # incrementale. IncrementalName webalizer.current # Il testo da visualizzare come titolo. In coda viene riportato # anche il nome dell'host webalizer è localizzato. ReportTitle “Usage Statistics for” # Definisce l'hostname per il report. # Viene usato sia nel titolo che nella tabella degli URL. # Questo parametro aiuta in presenza di virtual server o di # web server remoti. # Se non viene specificato viene usata la chiamata di sistema # standard per determinarne il nome. HostName linuxdidattica.org # L'estensione da postporre ai file di reports. # Possibili valori possono essere: php, phtml... HTMLExtension html # “PageType” specifica a webalizer i file di pagina. # Per la spiegazione leggere la sezione “Analisi dei risultati”. PageType htm* PageType cgi PageType phtml PageType php3 PageType php PageType pl # “DNSCache” specifica il nome del file di cache utilizzato per # lo reverse lookup se nei file di log viene individuato un # numero IP. # Se non viene speicficato un percorso il nome è relativo alla # directory di uscita. DNSCache dns_cache.db # Consente di specificare il numero di processi figli utilizzati # per il reverse lookup degli indirzzi IP. # Se viene specificato un numero diverso da zero, la cache verrà # aggiornata ad ogni avvio di webalizer e prima del processo di # analisi. # Il valore zero disabila la cache DNS. DNSChildren 5 # Elimina i messaggi di ouput, utile se webalizer viene avviato # da un cron job. Quiet no # A differenza del parametro “Quiet” disabilita anche i messagi di # errore e tutti i messaggi in generale. ReallyQuiet no # Imposta il default timeout in secondi per la visita o sessione. # Leggere il paragrafo “Analisi dei risultati”. VisitTimeout 1800 # Le parole chiave con “Top” definiscono il numero di entrate # visualizzabile per ogni tabella. Il parametro di default varia # secondo tabella. # Il valore di zero disabilita la tabella corrispondente. TopSites 30 TopURLs 30 TopAgents 15 TopCountries 50 TopEntry 10 TopExit 10 TopSearch 20 TopUsers 20 # Le parole chiave con “All” generano delle pagine HTMl separate # dove sono contenuti tutti gli URL, Sites, Referrers, User Agents, # Search Strings e Usernames. # Per raggiungere queste pagine viene aggiunto un link sotto alla # tabella relativa. AllSites yes AllURLs yes AllReferrers yes AllAgents no AllSearchStr yes AllUsers yes # Le parole chiave con “Hide”, “Group”, “Ignore” e “Include” # consento di modificare il comportamento di “Sites”, “URL”, # “Referrers”, “User Agents” e “Usernames”. # “Ignore” impone a webalizer di ignorare in modo completo il # recortd. # “Hide” non visualizza il record nella tabella top, tuttavia # viene contato nei totali. # “Group” raggruppa oggetti simili nella tabella “Top”. # questi oggetti non possono essere nascosti e non vengono contati # nella tabella totale. # Gli oggetti non vengono nascosti singolarmente, quindi si dovrà # eventualmente considerare un record Hide. # “Include” forza l'inserimento di record nel file di log. # hanno precedenza rispetto ad “Ignore”. # I valori possono essere completati per mezzo di wildcard “*”. HideSite localhost HideSite 217.57.34.98 HideSite *linuxdidattica.org HideSite 217.57.34.100 HideSite 192.168.* HideSite *.inf.besta HideSite *.mat.besta HideReferrer *linuxdidattica.org HideReferrer 217.57.34.98 HideReferrer 217.57.34.100 HideReferrer 192.168.* HideReferrer localhost HideReferrer *.inf.besta HideReferrer *.mat.besta HideURL *.gif HideURL *.GIF HideURL *.jpg HideURL *.JPG HideURL *.png HideURL *.PNG HideURL *.ra HideURL *.exe HideUser root HideUser admin GroupURL /cgi-bin/* CGI Scripts GroupURL /images/* Images IgnoreURL /scripts* IgnoreURL /*.exe IgnoreURL /c/* IgnoreURL /d/* IgnoreURL /MSADC/* IgnoreURL /msadc/* IgnoreURL /_vti_bin/* IgnoreURL /_mem_bin/* IgnoreSite *.inf.besta IgnoreSite *.mat.besta IgnoreSite 192.168.* IgnoreSite *linuxdidattica.org IgnoreSite localhost IgnoreURL /rapporti/* IgnoreURL *.css IgnoreURL /pagine_prova/ # “SearchEngine” viene usato per individuare la stringa immessa # per ricercare il sito con i motori di ricerca. SearchEngine yahoo.com p= SearchEngine altavista.com q= SearchEngine google.com q= SearchEngine eureka.com q= SearchEngine lycos.com query= SearchEngine hotbot.com MT= SearchEngine msn.com MT= SearchEngine infoseek.com qt= SearchEngine webcrawler searchText= SearchEngine excite search= SearchEngine netscape.com search= SearchEngine mamma.com query= SearchEngine alltheweb.com query= SearchEngine northernlight.com qr=
Non sono state documentare le parole chiave con “Dump” le quali consentono di memorizzare l'output in un formato importatibile in database SQL.
Ogni richiesta inviata al server (pagine html, file immagine, ...) viene registrata e classificata nell'output delle statistiche come “Hits”.
Le pagine html, come i file di immagine richiedono l'invio al client del contenuto stesso, questa azione viene registrata come file ed il contatore corrispondente “Files”, viene incrementato. Le “Hit” rappresentano i “colpi” in entrata, i “Files” le risposte in uscita.
Il contatore “Pages” rappresenta qualsiasi cosa che genera un documento in formato HTML, o un documento HTML stesso; sono esclusi quindi immagini, suoni, file compressi,... Generalmente viene considerato pagine tutto quello che termina con .html, .htm, .cgi, .php, .php3, .php4, .cgi. Il comportamento è modificabile.
Le richieste pervenute al server da un unico indirizzo IP vengono registrate nel contatore “Sites”.
Legato al contatore “Sites” c'è il contatore “Visits”; esso lega un valore di timeout, generalmente 30 minuti primi, per ogni “Sites”; se un “Sites” ritorna superato questo periodo viene incremntato il contatore “Visits”. Da questa considerazione si evince che questo parametro non dà un'analisi accurata del numero delle visite.
Il contatore “Kbytes” visualizza il numro di bytes in uscita prodotti dal web server, ossia il traffico prodotto dallo stesso.
I contatori “Entry Pages” e “Exit Pages” stimano il numero di URL usati per entrare nel sito monitorato e quale è l'ultima pagina visitata. Anche questa indicazione può non essere rigorosa per i limiti intrinseci del protocollo HTTP, tuttavia indica i trend di entrata ed uscita.
L'analisi dei log è molto importante soprattutto perché in caso di necessità potete subito verificare il traffico che il vostro server web genera e le stime di acceso ai contenuti in esso pubblicati.

Studentesse nel laboratorio Linux del “Besta”