Nella gestione di un sito web, come ad esempio il sito linuxdidattica.org, sito dedicato al progetto “Linux nella didattica”, e' importante farsi carico del fatto che sia accessibile ed usabile senza difficoltà dagli utenti. Questa facilitazione dovrà avvenire non solo con una costruzione non barocca del sito ma anche con strumenti di ricerca dell'informazione. E questa, a nostro parere, è una regola d'oro per ogni webmaster che si rispetti.
Al riguardo la comunità Open Source mette a disposizione un valido strumento: ‘ht://Dig’ come motore di indicizzazione delle pagine web. Il prodotto è accompagnato da licenza GPL (General public license) ed è reperibile per ogni distribuzione LiNUX, tuttavia gli aggiornamenti possono essere scaricati dall'indirizzo http://www.htdig.org.
Il software server/client ht://Dig è uno strumento per l’indicizzazione e ricerca di documenti web per piccoli e medi siti. Viene sfruttato in modo efficace se installato in una intranet.
Nonostante non sia indicato per complesse ricerche supporta: espressioni booleane, esclusione per robot, output configurabile, fuzzy logic come algoritmo, parole chiave da aggiungere ai documenti html, notifica con email per i documenti non più accessibili e/o non più presenti e porre limiti alla profondità della ricerca.
I documenti vengono indicizzati e memorizzati in un database interno. Per completare l’operazione è necessario disporre di un ragionevole quantitativo di spazio libero sul disco. Gli sviluppatori di ht://Dig consigliano di stimare lo spazio moltiplicando per 12000 (dodicimila) il numero di documenti se viene generato anche il database delle parole (wordlist) oppure per 7500 (settimilacinquecento) se non viene generato quest’ultimo database.
I programmi distribuiti con il pacchetto sono quattro: ‘htdig’, ‘htmerge’, ‘htnotify’, ‘htfuzzy’ e ‘htsearch’.
Htdig preleva le informazioni dai documenti (file html o di testo) con il protocollo http e costruisce il database, si può considerare come il cuore del pacchetto.
La sintassi del comando è le seguente: htdig [opzioni].
Le opzione ‘-c configfile’ indica il file di configurazione da utilizzare, per una distribuzione SuSE 7.3 il file di default è /opt/www/htdig/conf/htdig.conf.
L’opzione ‘-a’ indica di costruire una copia del database durante la ricostruzione dello stesso, occupa molto spazio, tuttavia consente di non bloccare il motore di ricerca (non sottovalutate questa opportunità spesso può richiedere molti minuti o ore!).
L’opzione ‘-s’ stampa statistiche finali.
L’opzione ‘-u username:password’ fornisce al programma una username ed una password se il server web protegge la directory dei documenti. L’unico algoritmo supportato è quello Basic.
L’opzione ‘-v’ visualizza utili informazioni durante la costruzione ed inizializzazione del database. Più di una v è utilie solo per debug del codice.
Htmerge crea una lista del database delle parole ed un indice dei documenti dei file creati con htdig.
La sintassi del comando rispecchia la precedente, le opzioni ‘-c’, ‘-a’, ‘-s’ e ‘-v’ sono equivalenti.
L’opzione ‘-w’ disabilita la costruzione del database delle parole.
L’opzione ‘-m configfile’ fa il merge dei due database.
L’opzione ‘-d’ disabilita la costruzione dell’indice dei documenti.
Htnotify esamina i documenti creati con htmerge ed invia una email se questi ultimi non sono più validi.
La sintassi del comando rispecchia le precedenti, le opzioni ‘-c’ e ‘-v’ sono equivalenti.
L’opzione ‘-b database’ carica un database diverso da quello indicato nel file di configurazione.
Htfuzzy crea più indici quanti sono gli algoritmi fuzzy utilizzati. Questi indici vengono usati da htsearch.
La sintassi del comando è la seguente: htfuzzy [opzioni] algoritmo.
Le opzioni ‘-c’ e ‘-v’ sono equivalenti a quelle precedentemente descritte; l’algoritmo può essere uno dei seguenti: soundex, metaphone, endings e synonims.
Htsearch è il motore di ricerca ed è uno script CGI, accetta sia il metodo POST che il metodo GET.
Per avviare la costruzione del database non è necessario lanciare singolarmente questi file, è spesso possibile utilizzare un semplice file di script ‘rundig’ che si occupa di ogni singolo passaggio.
[root /root]# rundig -a -s
Il fle di configurazione di ht://Dig ed usato da tutto il software è un file di testo dove ad ogni riga corrisponde un attributo, ossia una coppia nome variabile->valore.
I valori sono di tipo: stringa, lista di stringhe, numerici e booleani. I valori possono contenere riferimenti ad altri attributi, simile alle variabili usate in programmazione, come è possibile inserire il contenuto di un file come valore attraverso apici `file`.
Non tutti gli attributi sono usati dal software, l’amministratore non si deve occupare di separarne il contenuto. Non ce ne occuperemo in dettaglio, il file di configurazione standard fornito è più che sufficiente.
Una descrizione di alcuni di essi si può vedere nel listato n. 1.
# Listato n. 1
# file /etc/htdig.conf (Red Hat)
# file /opt/www/htdig/conf/htdig.conf (SuSE)
# Percorso dove i database vengono memorizzati.
database_dir: /var/lib/htdig
# Indica lURL di partenza, più URL vengono separate con lo spazio.
start_url: http://linuxdidattica.org
# Limita la ricerca dei documenti limitatamente ai siti in
# $start_url, scarta eventuali link presenti nelle pagine.
limit_urls_to: ${start_url}
# Indica i percorsi che non si vogliono indicizzare.
exclude_urls: /cgi-bin/ .cgi
# Lemail address del manteiner.
maintainer: root@localhost
# I documenti vengono prelevati sfruttando un proxy server.
http_proxy: http://proxy:3128
# In byte la quantità massima di informazioni prelevate da un
# documento.
max_doc_size: 500000
Non rimane che costruire il form da inserire nella pagina html. Al riguardo si veda il listato n. 2.
# Listato n. 2
<p align="center">
<form method="post" action="/cgi-bin/htsearch">
Cerca con:
<a href="http://www.htdig.org"><img src="/htdig/htdig.gif"
align="bottom" height="20" alt="ht://Dig"
border="0"></a> nel sito:<br>
Confronto:
<select name="method">
<option value="and">tutti
<option value="or">qualunque
<option value="boolean">booleano
</select>
formato:
<select name="format">
<option value="builtin-long">completo
<option value="builtin-short">breve
</select>
<input type="hidden" name="format" value="builtin-long">
ordinato per:
<select name="sort">
<option value="score">punteggio
<option value="time">data
<option value="title">titolo
<option value="revscore">pungeggio inverso
<option value="revtime">data inversa
<option value="revscore">pungeggio inverso
<option value="revtime">data inversa
<option value="revtitle">titolo inverso
</select>
<input type="hidden" name="config" value="htdig">
<input type="hidden" name="restrict" value="">
<input type="hidden" name="exclude" value="">
ricerca:
<input type="text" size="15" name="words" value="">
<input type="submit" value="invio"></form>
</p>
Nella directory /usr/share/htdig (oppure /opt/www/htdig/common per SuSE) ci sono i file in formato html (syntax.html, header.html, nomatch.html, wrapper.html, footer.html, long.html, short.html) da modificare per adattare l’output nella propria lingua.
Il file html dovrà contenere almeno un campo di input testuale con il nome di “words” dove il navigatore inserirà la stringa di ricerca. Gli altri sono opzionali e consentono di personalizzare la ricerca.
Da ricordarsi che ogni volta che si modificano significativamente i contenuti del sito bisogna rilanciare htdig. Per facilitare il compito si può inserire il comando rundig senza l'opzione -a nella directory che contiene gli script del comando cron. Con una distribuzione Red Hat le directory sono : /etc/cron.daily, /etc/cron.weekly, /etc/cron.montly.
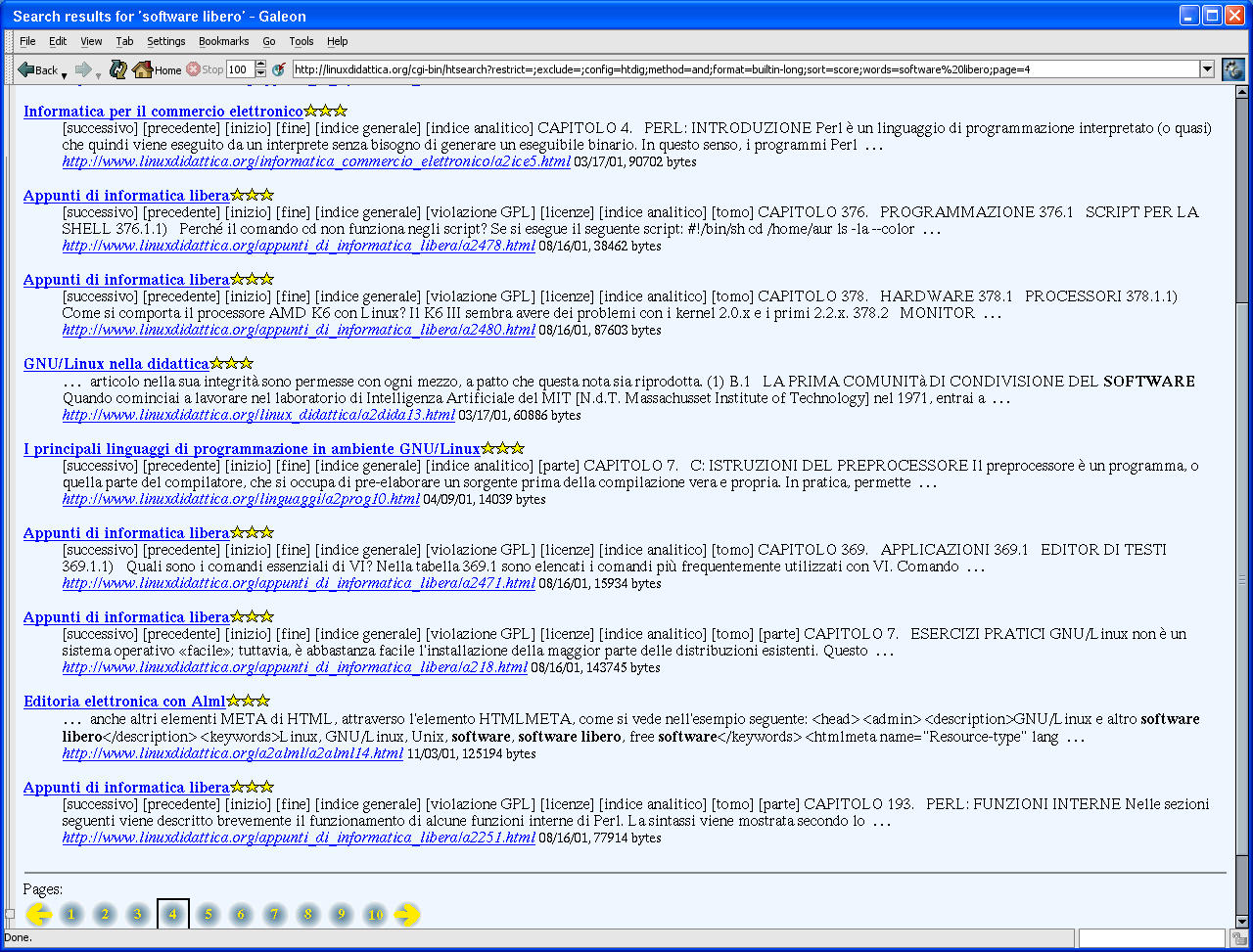
Nella figura n. 1 è visibile il risultato della ricerca per la stringa 'software libero'.
Nella figura n. 2 la ricerca si riferisce alla stringa 'postgresql' in formato breve.
Fig. 1
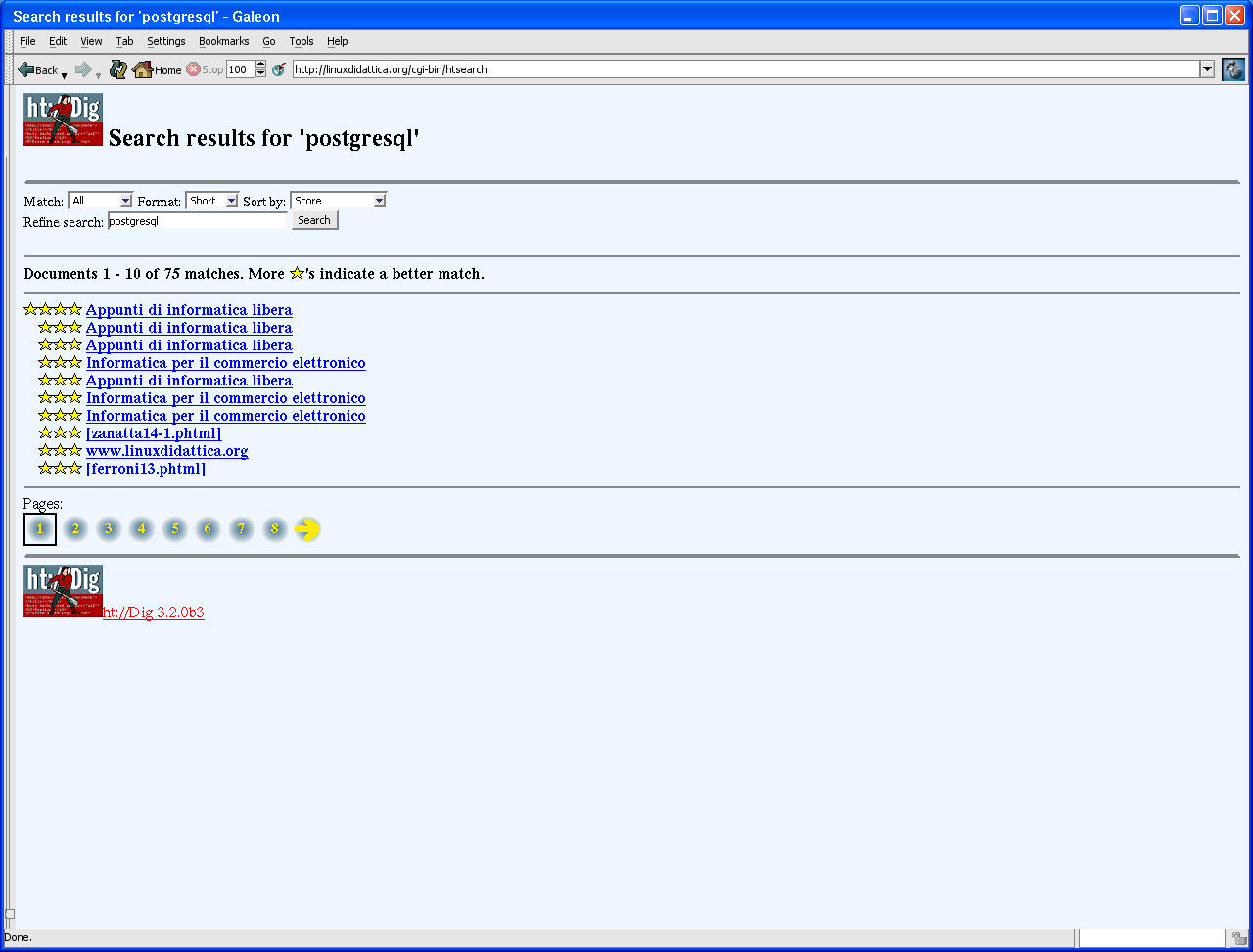
Fig. 2