File system distribuiti [parte 1]
Un filesystem distribuito memorizza file [siano essi file o directory] in uno o più computer che fungono da file server e li rende fruibili ad altri che fungono da client.
La distribuzione di file da un server verso più client con il sistema operativo GNU/Linux viene generalmente realizzata adoperando l'NFS [Network file system]. I vantaggi sono, più che altro, legati alla facilità di realizzare una soluzione server/client «subito operativa»: gestione a livello kernel oramai consolidata, disponibilità di solidi strumenti di amministrazione, installazione e configurazione relativamente semplice e interoperabilità con tutti gli ambienti Unix-Like.
Un file system distribuito non si incarica solamente di inviare e ricevere dati in rete ma anche di garantire un affidabile sistema di immagazzinamento, ridondanza e recupero [attraverso anche copie in più server] degli stessi in caso di blocco del sistema. L´organizzazione è appunto distribuita, contrariamente alla architettura del file system in NFS o Samba. Lo scopo è quello di memorizzare le directory ed i file sotto un´unica directory radice ed ogni volume o sistema di file [si veda il concetto più avanti] viene in essa innestato e visto immediatamente da tutti i client sotto quest´utlima.
Le caratteristiche aggiunte in un file system distribuito sono:
possibilità di operare fuori rete come nel caso di computer portatili;
recupero ed integrazione dei dati per i computer una volta connessi;
possibilità di distribuire ed immagazzinare i dati in più server;
risoluzione dei conflitti client/server e server/server;
coerenza dei file e directory lato client con meccanismi sicuri di caching;
meccanismi di autenticazione sicuri;
meccanismi di accesso ai file basati su ACL [Access Control List].
Per l´ambiente GNU/Linux sono disponibili più file system distribuiti tra i quali OpenAFS [http://www.openafs.org], derivato dalla versione commerciale AFS [pioniere nei file system distribuiti], InterMezzo [http://www.inter-mezzo.org] e CODA [http://www.coda.cs.cmu.edu]. Gli ultimi due sono integrati nel kernel 2.4. In questi articoli verrà introdotto il file system CODA sviluppato dalla Carnegie Mellon University originariamente per kernel Mach 2.6 e il file system InterMezzo.
CODA viene fornito come modulo per il kernel per quanto concerne la parte client e una serie di strumenti di amministrazione distinti per la parte server e client. Gli strumenti di amministrazione e la gestione del file system è ispirata al file system AFS. Non rende i due sistemi interoperabili, ma ne facilita la migrazione.
Dal sito web è possibile scaricare gli ultimi aggiornamenti dei pacchetti di amministrazione sia per Linux RedHat [in formato rpm] sia per Debian GNU/Linux [in formato deb] per piattaforma x86. Dalla pagina iniziale vi sono i riferimenti per accedere alla documentazione e alla lista di discussione legata al progetto. Oltre ai sistemi GNU/Linux, CODA è stato portato in sistemi NetBSD, FreeBSD ed alcune versioni di Windows.
Per installare i pacchetti in una distribuzione Debian è sufficiente aggiornare il file /etc/apt/source.list:
# Coda
deb http://www.coda.cs.cmu.edu/pub/coda/linux debian/binary-i386/
Utilizzare i programmi `dselect´ o `apt-get´ per installare i pacchetti di amministrazione e le librerie correlate. Per una configurazione server è disponibile il pacchetto `coda-server´; per una configurazione client è disponibile il pacchetto `coda-client´.
Nel caso i programmi non siano precompilati per la vostra distribuzione preferita allora, bisogna scaricare i pacchetti in formato compresso: `lwp´, `rpc2´, `rvm´ e `coda´ e compilarli.
La compilazione avviene in modo distinto e, rispettando l´ordine di priorità, con i comandi seguenti:
# ./configure –-prefix=/usr –-sysconfdir=/etc;
# make install
Se nel sistema client non è presente il modulo `coda.o´ o in generale non è previsto il supporto a CODA è necessario configurare, ricompilare ed installare un nuovo kernel con esso attivo.
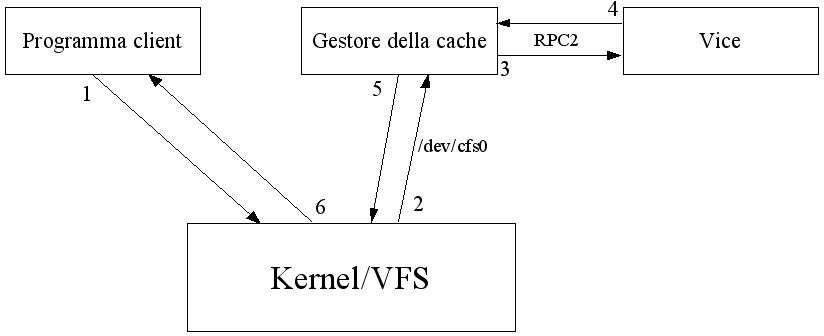
Il modulo `coda.o´ serve al gestore della cache lato client per comunicare con il kernel attraverso il file di dispositivo /dev/cfs0 o /dev/coda/* se si utilizza lo devfs [vedi fig. 1].
Gli strumenti di amministrazione possono sembrare perniciosi e sicuramente non allineati alla sintassi e alla «pulizia» del sistema operativo GNU/Linux e dei comandi in generale; altra caratteristica è la gestione di un sistema di accreditamento utenti e gruppi di tipo proprietario.
InterMezzo è nato in GNU/Linux e rimarrà un progetto tale. Pur non offrendo tutte le importanti caratteristiche di CODA è più leggero e ben integrato nel sistema operativo e utilizza file di configurazione in formato aperto basati su XML.
La coerenza delle operazioni in caso di lavoro fuori rete o, nel caso peggiore, di crollo del sistema è garantita dal gestore della cache lato client.
Le attività sui file vengono gestite da una chiamata di sistema che interroga il kernel per effettuare le operazioni necessarie.
Le attività sulla directory /coda sono gestite da CODA attraverso Venus, il gestore della cache. Il compito di Venus è quello di risolvere i conflitti tra la cache presente nel client ed i file presenti nel server. Per operare più velocemente CODA interroga sempre la cache [memorizzata in /usr/coda/venus.cache], se il file nel server non è stato modificato allora l´operazione viene eseguita in locale velocizzandola. Se invece il file non è presente in cache allora coda recupera l´informazione dal server attraverso una procedura di chiamata remota [RPC2] e memorizza il file nella cache del client.
Le modifiche vengono propagate dal client al server in un secondo momento. In caso il client operi modifiche ai file fuori rete il gestore della cache memorizza ogni attività nel file di registro in modo trasparente all´utente. Al successivo riavvio del server i dati vengono sincronizzati.
Se durante l´aggiornamento del server vi è un conflitto [local/global conflitct] tra file [due utenti hanno lavorato sul medesimo file, per esempio] CODA cerca di risolverlo; nel caso peggiore è indispensabile operare manualmente con l´apposito strumento lato client.
Un´altra peculiarità di CODA è quella di poter «ammassare» i file più importanti nella cache del client al posto di quelli meno usati frequentemente. In questo caso viene costruito un database [hoard database] dei programmi o file più usati, così facendo nel caso di utilizzo del computer per lungo periodo fuori rete [come nel caso di un portatile] i file sono mantenuti dal gestore della cache.
Per volume si intende una parte del disco che occupa meno spazio di una partizione ma, più spazio di una directory.
I file nel server CODA non sono organizzati in modo tradizionale; ad ognuno di esso viene assegnato un identificativo o una terna di numeri detta Fid. Essa consiste di un identificatore di volume, di un identificatore di inode e di un qualificatore per risolvere il nome. Il Fid è unico per ogni file. I metadata di questi file sono memorizzati nella RVM. Combinati assieme i dati e i metadati, questi vengono visti dal lato client come file e directory sotto /coda.
I file e le directory sono memorizzati in volumi; la home directory potrebbe essere contenuta in un volume, la directory dei documenti in un altro e così via. Ogni partizione [/vicepx] può contenere più volumi, generalmente un buon compromesso è attorno ai 10 Mb per ognuno.
Dal lato client questi volumi vengono innestati come sottodirectory della directory radice [/coda]. Il meccanismo è simile a quello del comando `mount´ Unix, tuttavia ad ogni innesto viene creata una nuova directory.
La ridondanza in CODA è spinta al punto tale che questi volumi possono essere replicati in gruppo di server detti VSG [Volume storage group] ognuno dei quali ne mantiene una copia speculare.
A differenza del file system tipo NFS o Samba, CODA ha un unico punto di innesto [spazio dei nomi] dove tutti i client fanno riferimento: questo corrisponde, come già detto, alla directory /coda. I file in questa directory sono visibili a tutti i client. In un certo senso un client si «connette a CODA» e quindi in modo trasparente al server! Dal lato server è possibile invece organizzare e distribuire la gestione dei file in più directory. Queste directory per default hanno percorso /vicepa, /vicepb... e devono necessariamente essera una ed una sola per ogni partizione del disco.
CODA può essere organizzato a celle [coda cell] dove un gruppo di server condividono le stesse informazioni. Un server principale detto SCM [System control machine] si incarica di distribuire le informazioni a tutti gli altri dei dati contenuti in /vice/db per mezzo del file /vice/db/file.export. Un client CODA può comunicare solo con una singola cella.
Il file server CODA organizza la struttura delle directory ed i file in volumi [coda volumes]. Ogni volume viene innestato nella directory /coda del client, che rappresenta il volume principale, come sottodirectory e può contenere a sua volta file e directory. L´insieme dei server che servono un volume viene detto VSG [Volume Storage Group]. L´innesto dei volumi non viene perso al riavvio del sistema quindi l'operazione viene effettuata una volta sola.
Il sistema di immagazzinamento dei dati di CODA [Data Storage] si basa su un meccanismo che identifica i file attraverso un numero e un metadato. I file vengono memorizzati nelle directory /vicepx i metadati nella partizione o file generici creati durante l´installazione. L´integrità dei metadati viene garantita dal meccanismo RVM [Recoverable virtual memory]. I dati vengono registrati in modo permanente sul disco grazie al passaggio tra l´indirizzo virutale assegnato al file, dove avvengono le modifiche, e quello fisico che serve per la memorizzazione su disco fisso. I dati prossimi alla registrazione su disco ma, non ancora avvenuta, sono memorizzati nel file o partizione di registro [stesso principio delle transazioni adoperate nei database].
Dal lato client le attività non subiscono modifiche sostanziali: i metadati sono registrati generalemente nel file /usr/coda/DATA mentre la cache dei file in /usr/coda/venus.cache. Quest´ultima è fondamentale quando si opera fuori rete. Il gestore della cache di CODA preleva le informazioni necessarie da essa. Ad ogni nuovo collegamento con il server gestore del volume il file presente nel server viene convalidato in qualche modo con quello presente nel client. L'operazione di reintegro dei dati dovrebbe avvenire senza interventi da parte dell´amministratore; tuttavia se si generano conflitti irrisolvibili per CODA, questi vanno risolti intervenendo manualmente.
I meccanismi di protezione e di autenticazione vengono gestiti attraverso un gettone [token] fornito dal server. Ogni utente deve autenticarsi via Venus con il server altrimenti il suo accesso rimarrà con i permessi dell´utente anonimo.
I complicati meccanismi per garantire l´integrità dei dati necessitano di ampio spazio su disco per consentire di registrare tutte le operazioni effettuate sui file. Per questo prima di installare CODA è obbligo verificare lo spazio su disco per una configurazione puramente di test. Operativamente è consigliabile creare delle partizioni, meglio in un secondo disco fisso, per contenere i metadati e i file di registro.
Lo script che genera la configurazione del server coda viene lanciato da super utente con il comando:
# vice-setup[Invio]
Vice viene identificato come il gestore server di CODA.
Dopo aver individuato la directory dove memorizzare i file di gestione di CODA e il file di configurazione [lasciare le impostazioni predefinite].
Is this the master server, aka the SCM machine? (y/n) y
Rispondere y se il server che state configurando funge da SCM.
Setting up tokens for authentication.
The following token must be identical on all servers.
Enter a random token for update authentication : abcdefgh
Digitare una chiave di almeno otto caratteri che corrisponde ad uno dei tre gettoni utilizzati per i meccanismi di autenticazione di CODA rispettivamente: `update´, `auth2´ e `volutil´. Ogni server appartenente alla cella dovrà utilizzare le stesse chiavi casuali.
The serverid is a unique number between 0 and 255.
You should avoid 0, 127, and 255.
serverid: 1
Digitare un numero unico compreso tra 0 e 255 esclusi 0, 127 e 255 che identifica il server. Gli altri server della cella non possono avere lo stesso numero.
Enter the name of the rootvolume (< 32 chars) : codaroot
Il nome del volume radice l´unico che non deve essere innestato.
Enter the uid of this user: 1002
Enter the username of this user: codadmin
Digitare la uid o lo username dell´amministratore del server CODA. Questo non deve assolutamente avere uid posta a 0 e username posta a root. È preferibile utilizzare la uid e la username dell´utente generico utilizzato dall´amministratore del sistema.
Are you ready to set up RVM? [yes/no] yes
What is your log partition? /vice/log
Imposta il file o la partizione di LOG utilizzata da CODA. Nel caso di un´installazione per puro test scrivere il nome di un file.
The log size must be smaller than you log partition. We
recommend not more than 30M log size, and 2M is a good choice.
What is your log size? (enter as e.g. '2M') 2M
Un file di registro molto grande può rallentare sensibilmente le operazioni. Se si è scelto una partizione verificare che la quantità inserita non superi le dimensioni della stessa.
What is your data partition (or file)? /vice/data
What is the size of you data partition (or file)
[22M, 44M, 90M, 130M, 200M, 315M]: 22M
Le dimensioni del file di metadata devono raggiungere in modo approssimativo il 4% delle dimensioni destinate all´immagazzinamento dei dati. CODA consiglia valori compresi tra i 500M e gli 8G byte di dati. Per una configurazione di test tenere il valore di 22M.
Your server directories will hold the files (not directories).
You can currently only have one directory per disk partition.
Where shall we store your file data [/vicepa]?
Shall I set up a vicetab entry for /vicepa (y/n) y
Select the maximum number of files for the server.
[256K, 1M, 2M, 16M]:
256K
Il numero massimo di file che il server può memorizzare. Questa non è una caratteristica documentata tuttavia 256K è un valore ragionevole.
Conclusa l´installazione è possibile avviare il server CODA.
# /etc/init.d/auth2.init start[Invio]
# /etc/init.d/coda-update start[Invio]
# /etc/init.d/codasrv.init start[Invio]
CODA registra le informazioni di avvio in più file di registro.
# cat /vice/srv/SrvLog[Invio]
16:21:54 File Server started Fri Jan 17 16:21:54 2003
# cat /vice/auth2/AuthLog[Invio]
16:21:41 Server successfully started
Visualizzare le informazioni di questi file per controllare se i servizi si sono avviati in modo corretto.
Le ultime due operazioni da fare per essere operativi sono: cambiare la password dell´amministratore di CODA, creare il volume di radice. CODA non utilizza il sistema di autenticazione delle password di Unix; in fase di configurazione viene assegnato all´amministratore [nel nostro caso codadmin] la password «changeme».
# au -h 172.17.1.254 cp
Your Vice name: codadmin
Your password: changeme
RPC2_Bind() --> RPC2_SUCCESS
User name: codadmin
New password: abcdefgh
AuthChangePasswd() --> AUTH_SUCCESS
L´opzione `-h´ indica l´indirizzo IP o il nome di host del server SCM; la passoword può essere modificata solamente contattando il server SCM.
# createvol_rep codaroot E0000100 /vicepa
Crea il volume radice. Il primo argomento rappresenta il nome dato al volume che deve essere lo stesso indicato durante la fase di configurazione. Il secondo indica il gruppo VSG di appartenza. Nel nostro caso il server SCM appartiente al gruppo E0000100 [il file che associa un server ad un gruppo è /vice/db/VSGDB].
In questo primo articolo si è introdotto il concetto di file system distribuito ed è stata completata una installazione server di CODA. Nel prossimo verrà discusso l´utilizzo di CODA dal punto di vista client con la creazione di utenti e le verifiche di funzionamento.